

| Alex X. Lee | Richard Zhang | Frederik Ebert | Pieter Abbeel | Chelsea Finn | Sergey Levine |
| University of California, Berkeley |
| Code [GitHub] | arXiv [preprint] |
|
|
|
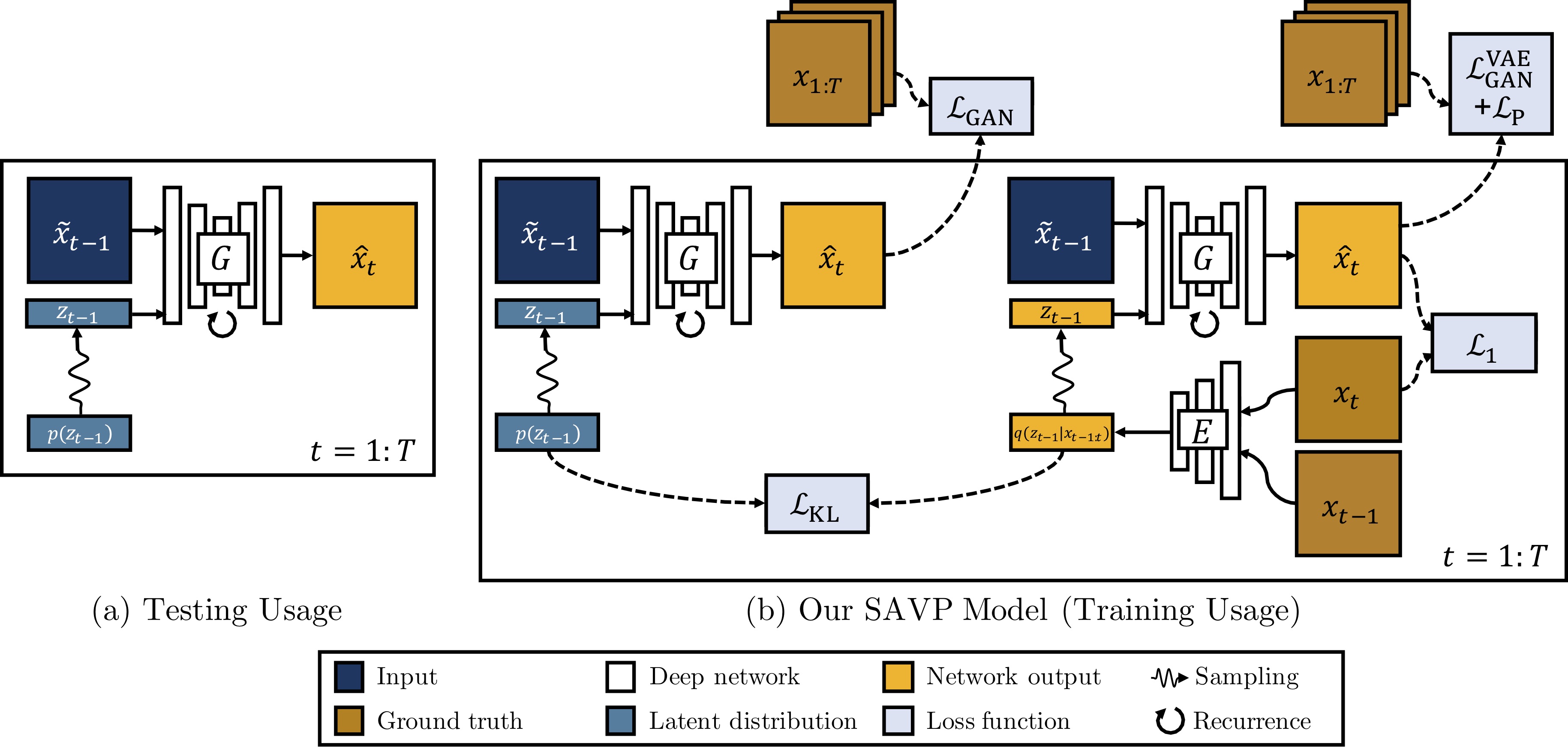
|
| [GitHub] |

|
A. X. Lee, R. Zhang, F. Ebert, P. Abbeel, C. Finn, S. Levine Stochastic Adversarial Video Prediction. arXiv (preprint). |
| [Bibtex] |
| BAIR action-free robot pushing dataset |
    |
| [All test set] [Random samples] [Diversity visualization] |
|
BAIR action-free robot pushing dataset (500 time-steps) |
  |
| [Random samples (500 time-steps)] |
| KTH human actions dataset |
      |
| [All test set] [Random samples] |
| BAIR action-conditioned robot pushing dataset |
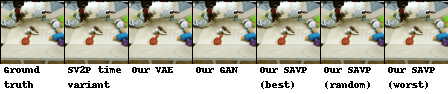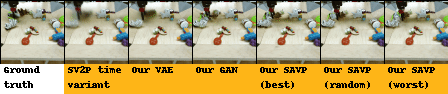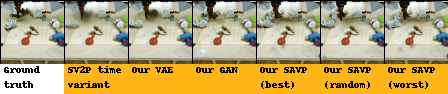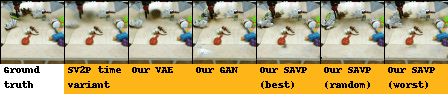 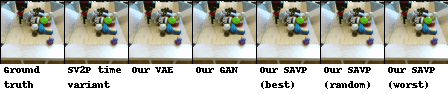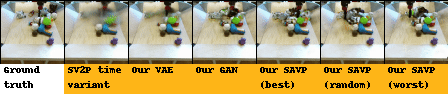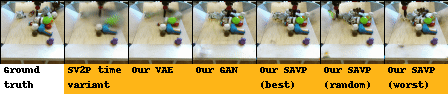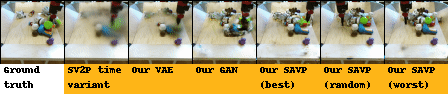 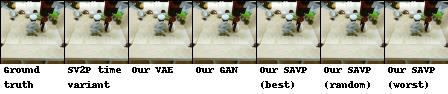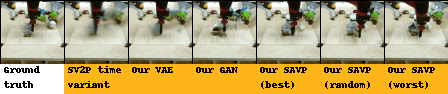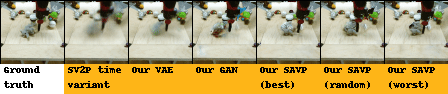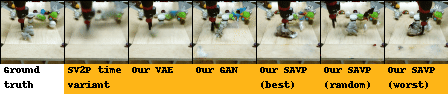  |
| [All test set] |
| We thank Emily Denton for providing pre-trained models and extensive and timely assistance with reproducing the SVG results, and Mohammad Babaeizadeh for providing data for comparisons with SV2P. This research was supported in part by the Army Research Office through the MAST program, the National Science Foundation through IIS-1651843 and IIS-1614653, and hardware donations from NVIDIA. Alex Lee and Chelsea Finn were also supported by the NSF GRFP. Richard Zhang was partially supported by the Adobe Research Fellowship. |